
When building statistical models in educational research or predictive analytics, one of the most important considerations is ensuring the model generalizes well to new data. This blog will focus on two fundamental concepts: cross-validation and overfitting, and how they relate to ensuring model robustness.
What is Overfitting?
Overfitting occurs when your model fits not just the underlying signal in your data but also the noise. This leads to a model that works well on your training data but performs poorly on unseen data. Overfitting happens when the model becomes too complex, capturing every fluctuation in the data, even those that aren’t meaningful.
Consider the example of predicting student exam performance based on study habits. If you build a model that overly adapts to every minute detail, like the exact number of study breaks, your model may seem perfect on the training data but fail when predicting new students’ performance.
Below is an illustration of under-fit vs good fit vs overfit:
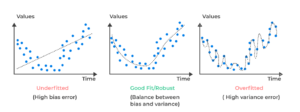
On the left, you see a trendline that is too simple to capture the underlying patterns in the data. The straight line fails to capture the curvature of the data points, resulting in large deviations between the model and the actual data. In the middle, you see a smooth curve that captures the general trend of the data without being overly complex, providing a good fit to the underlying pattern. This model captures the essential signal. On the right, the model zigzags through every point, capturing the noise, which results in a model that won’t generalize to new data.
How to Reduce Overfitting?
There are several techniques to reduce overfitting:
- Simpler Models: Use fewer variables to make the model less complex. In the context of university performance prediction, instead of considering every minute factor (like precise study durations), you could focus on broader variables such as total study hours or number of assignments completed.
- Regularization: Methods like AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) help select models with fewer parameters by penalizing excessive complexity.
- Cross-Validation: This is a crucial method for reducing overfitting. By dividing your dataset into multiple subsets and testing the model on unseen subsets, you can better understand how well your model will generalize to new data.
Understanding Cross-Validation
One popular cross-validation method is k-fold cross-validation, where the data is divided into k groups or “folds.” The model is trained on all but one fold and tested on the remaining fold. This process repeats, with each fold taking a turn as the test set. The final performance is the average performance across all k folds.
Let’s say you have student data and split it into 5 folds. You train the model on 4 folds and test it on the last fold. By cycling through all combinations, you ensure that the model has been tested on every data point.
Training Set vs Test Set
In simpler terms, cross-validation solves the problem of an uneven distribution of data between training and test sets. If you were just using a single training/test split, the test set might not be representative of the overall data. Cross-validation ensures that each subset of the data is tested.
In educational contexts, this might mean using data from previous semesters to predict student outcomes in future semesters. By cross-validating, you ensure that your model isn’t just tuned to a specific group of students but generalizes across different cohorts.
Choosing the Right Cross-Validation Method
In educational research, it’s essential to choose the correct type of cross-validation:
- Flat Cross-Validation: Every data point has an equal chance of being included in any fold. This is the most basic method and often sufficient for standard data sets.
- Stratified Cross-Validation: This ensures each fold has a similar proportion of data points for certain important variables (like student demographics or grades), ensuring more representative test sets.
- Student-Level Cross-Validation: Particularly useful in education, this ensures that no student appears in both the training and test sets, which is critical when building models intended to predict new student outcomes.
Practical Example in University Context
Let’s take an example from educational analytics: predicting whether students will pass or fail a course based on their engagement with a learning management system (LMS). You want to avoid overfitting by ensuring the model isn’t biased to particular semesters or student cohorts.
Using cross-validation, you could partition the data by semester, training the model on some semesters and testing it on others. Alternatively, student-level cross-validation could ensure that no single student’s data is used both for training and testing.
Ultimately, the goal is to create a model that performs well on new, unseen data. This is especially crucial in educational contexts where models often need to predict outcomes for new cohorts of students. Using cross-validation ensures your model doesn’t overfit to one particular group of students, improving its generalizability.
Types of Validity
Validity is multi-dimensional, encompassing generalizability, ecological validity, construct validity, and more. Understanding these concepts ensures that your models in educational data mining are reliable, meaningful, and applicable across different contexts. Whether you’re predicting student engagement, dropout rates, or performance on standardized exams, addressing each type of validity is crucial for building models that truly make an impact.
1. Generalizability: Can Your Model Handle New Data?
Generalizability refers to how well a model developed in one context applies to new data or different contexts. This is a key consideration in cross-validation, which is a widely used method in data mining to assess how a model will perform on unseen data.
Example: Generalizability Fail
Imagine building a model that detects boredom using data from just three students. If this model fails when applied to new students, it means it lacks generalizability. A related issue is detector rot, where a model works initially but fails over time as conditions change. For instance, a model built to detect at-risk students pre-COVID might break down during the pandemic because student behaviors or societal conditions have changed.
2. Ecological Validity: Can Your Model Be Applied in Real-World Settings?
Ecological validity ensures that findings from research can be applied in real-world environments. This is particularly important when transitioning from controlled lab settings to dynamic, real-life classrooms.
Example: Ecological Validity Fail
Let’s say you build a model to detect off-task behavior in a lab, where students are quietly sitting alone. When you apply the model to a real classroom, where students might chat with their neighbors or engage in different ways, your model may fail because the behavior is different. In the lab, students might simply glance at their phones, while in a classroom, they might be distracted by conversations.
3. Construct Validity: Are You Measuring What You Intend to Measure?
Construct validity evaluates whether your model measures the concept it’s intended to measure. For example, if you are modeling student engagement, are you sure that your data actually reflect engagement?
Example: Construct Validity Fail
Consider a scenario where you’re trying to predict which students will be sent to alternative schools based on disciplinary records. If your “alternative school” label also includes students with developmental disabilities sent to special schools, the construct you are measuring is no longer just disciplinary problems—it’s something more complex.
4. Predictive Validity: Can Your Model Predict the Future?
Predictive validity refers to whether a model not only describes current patterns but also predicts future outcomes accurately. This is crucial for models used in educational settings where predictions can impact student trajectories.
Example: Predicting Boredom and Future Success
For instance, boredom has been shown to predict disengagement, lower standardized test scores, and even long-term outcomes such as college attendance. A model that predicts future learning outcomes based on current behaviours (like boredom) would have high predictive validity. In contrast, predicting whether a student is a “visual learner” may not correlate strongly with future learning outcomes, indicating lower predictive validity.
5. Substantive Validity: Do Your Results Matter?
Substantive validity questions whether the outcomes your model predicts are meaningful in practice. Is your model contributing to scientifically valuable insights or practical applications in education?
Example: Predicting Relevant Constructs
If a model predicts disengagement or dropout rates, its findings can have a direct impact on how schools intervene and support students. On the other hand, a model predicting whether students prefer visual or verbal learning styles might not be as useful, especially if these preferences don’t correlate well with actual learning outcomes.
6. Content Validity: Does Your Model Capture the Full Range?
Content validity ensures that the model covers all the relevant behaviors or variables it’s intended to measure. In educational data mining, this means making sure your model captures all forms of a behavior.
Example: Gaming the System
Consider a model that detects students who are “gaming the system” by guessing answers to bypass learning. If the model only captures one type of gaming (like random guessing) but ignores other forms (such as abusing hints), it lacks content validity. A model that captures multiple gaming strategies is more valid in terms of content coverage.
7. Conclusion Validity: Are Your Conclusions Justified?
Conclusion validity focuses on whether the conclusions you draw from your data and model are well-supported by the evidence. It’s important to ensure that your findings are logically sound and statistically robust.
Reference:
Baker, R.S. (2024) Big Data and Education. 8th Edition. Philadelphia, PA: Universiwty of Pennsylvania.








